Ligue 1 Statistieken voor Wedden: Data die het Verschil Maakt
Inhoudsopgave
- Waarom ruwe data niet genoeg is voor slim wedden
- Basisstatistieken: doelpunten, punten en ranglijst lezen
- Geavanceerde statistieken: wat ze zijn en waar ze helpen
- Waar vind je betrouwbare Ligue 1 statistieken?
- Van data naar weddenschap: een praktijkvoorbeeld
- Veelgestelde vragen over Ligue 1 statistieken en wedden
Waarom ruwe data niet genoeg is voor slim wedden
Twee seizoenen geleden baseerde ik een weddenschap op het feit dat Nantes de meeste clean sheets had van alle Ligue 1 clubs in de eerste tien speelrondes. Ik zette op under 2.5 bij hun volgende thuiswedstrijd. Nantes verloor met 3-1. Wat was er misgegaan? De clean sheets waren geflatteerd — Nantes had in die wedstrijden een expected goals against van 1.4 per wedstrijd, maar de tegenstanders misten kans op kans. De ruwe data vertelde een mooi verhaal. De onderliggende statistieken vertelden de waarheid.
Dat is het verschil tussen data gebruiken en data begrijpen. De Ligue 1 genereert per seizoen duizenden datapunten: 2,96 doelpunten per wedstrijd gemiddeld, honderden clean sheets, duizenden schoten. Die cijfers zijn vrij beschikbaar. Maar de wedder die alleen naar doelpunten en punten kijkt, mist het mechanisme erachter. Hoeveel van die doelpunten kwamen voort uit echte kansen? Hoeveel punten werden gewonnen door geluk in plaats van prestatie?
In dit artikel leg ik uit welke statistieken er werkelijk toe doen bij het wedden op de Ligue 1 — van de basisgegevens die iedereen kent tot de geavanceerde metrics die het verschil maken. Niet als theoretisch overzicht, maar als praktische handleiding: welke cijfers zoek je op, waar vind je ze, en hoe vertaal je ze naar een weddenschap met waarde? We eindigen met een compleet praktijkvoorbeeld waarin ik alle statistieken combineer tot een concrete tip. Dat voorbeeld is de kern van dit artikel, want statistieken zonder toepassing zijn trivia — pas in de vertaling naar een weddenschap worden ze waardevol.
Basisstatistieken: doelpunten, punten en ranglijst lezen
Het klassement is de meest geraadpleegde statistiek en tegelijk de meest misleidende. Ik heb het zo vaak gezien dat het bijna een cliche is geworden. Een club op plek vier na tien speelrondes lijkt een stabiele bovenlaag-club. Maar als die club vier van zijn vijf overwinningen behaalde in de eerste vijf ronden en sindsdien alleen maar punten verliest, vertelt het klassement een verouderd verhaal. Het klassement is een foto, geen film.
Doelpunten per wedstrijd zijn de eerste laag onder het klassement. Het seizoensgemiddelde van de Ligue 1 in 2025/26 — 2,96 per wedstrijd — is een bruikbaar referentiepunt. Teams die structureel boven dat gemiddelde scoren, zijn kandidaten voor over-weddenschappen. Teams die eronder zitten, voor under. Maar ook hier geldt: het totaal verbergt de details. Een team dat gemiddeld 1.8 doelpunten per wedstrijd maakt, maar thuis 2.4 en uit 1.2, is een totaal ander profiel voor een thuiswedstrijd dan voor een uitwedstrijd.
56% van de Ligue 1 wedstrijden eindigt met meer dan 2,5 doelpunten. Dat percentage is een startpunt voor de over/under markt, maar niet meer dan dat. De spreiding per team is enorm. Sommige clubs — vooral de aanvallend ingestelde middenmoters — produceren wedstrijden met gemiddeld 3,5 doelpunten. Andere — de defensieve degradatiekandidaten — zitten op 2,0. Die spreiding is precies de informatie die je nodig hebt om de standaard over/under lijn van 2.5 te evalueren per specifieke wedstrijd.
Punten per wedstrijd, gesplitst in thuis en uit, is een statistiek die ik in elke analyse gebruik. Het verschil tussen een thuispuntgemiddelde van 2.1 en een uitpuntgemiddelde van 0.9 vertelt me dat een team thuis een ander niveau speelt. Dat is niet verrassend, maar de grootte van het verschil varieert per club en per seizoensfase. Een team dat in de eerste helft van het seizoen thuis sterk is maar na de winterstop inzakt, biedt in januari nog steeds hoge quoteringen op basis van het seizoensgemiddelde — een gemiddelde dat door de goede eerste helft is opgeblazen.
Geavanceerde statistieken: wat ze zijn en waar ze helpen
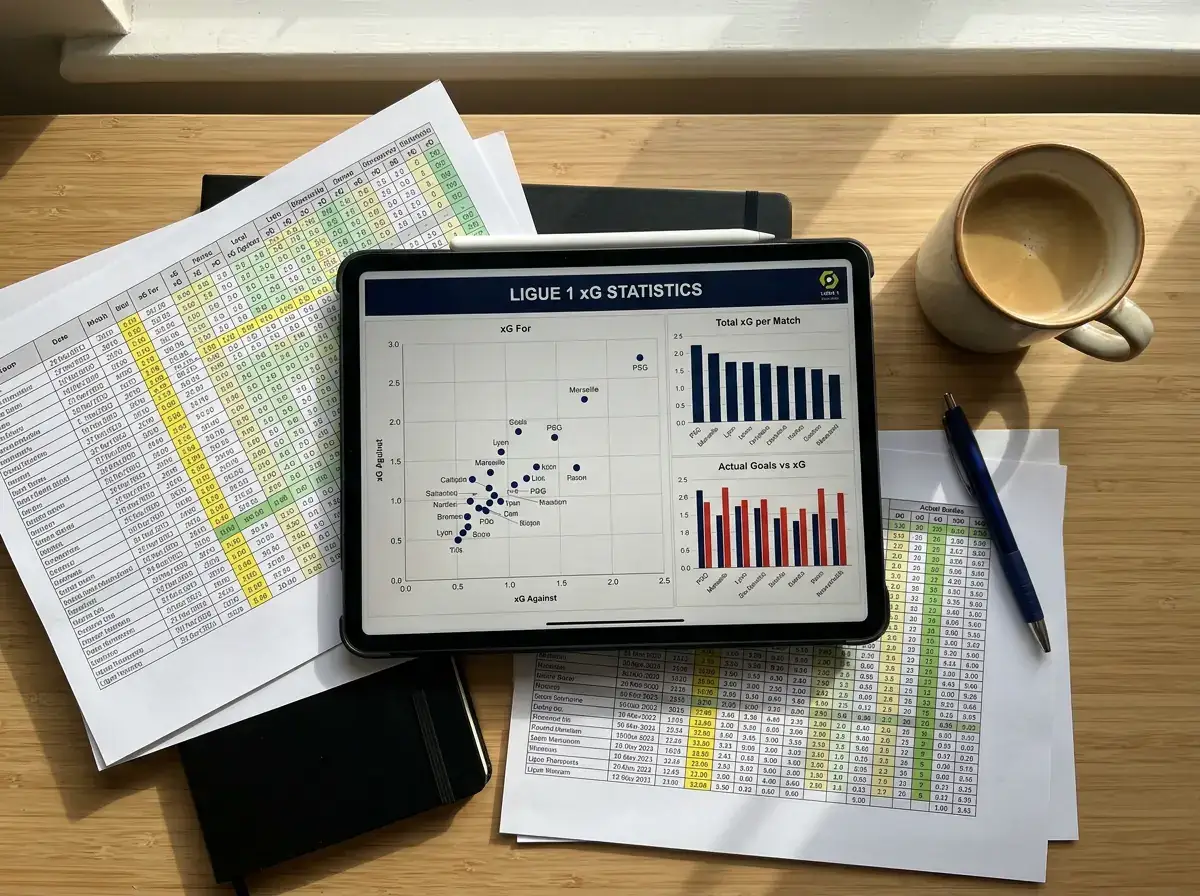
Expected goals — xG — is de statistiek die de afgelopen tien jaar het wedden op voetbal het meest heeft veranderd. Het concept is simpel: elke schotkans krijgt een waarde tussen 0 en 1, gebaseerd op de positie van het schot, de hoek, het type (kop, linkervoet, rechtervoet), en of het uit open spel of een standaardsituatie kwam. Een penalty heeft een xG van ongeveer 0.76. Een kopbal van buiten het strafschopgebied zit onder de 0.03. Het totaal van alle schotkansen in een wedstrijd geeft de xG van een team — een maatstaf voor hoeveel doelpunten je zou verwachten op basis van de kwaliteit van de kansen.
In de Ligue 1, met achttien teams in het seizoen 2025/26, is xG bijzonder nuttig vanwege de grote kwaliteitsverschillen. PSG genereert regelmatig een xG van 2.5 of hoger per thuiswedstrijd, terwijl een degradatiekandidaat soms op 0.6 blijft steken. Dat verschil is groter dan in de Premier League, waar de selecties gelijkmatiger zijn verdeeld. De consequentie voor wedders: xG helpt je om te bepalen of een uitslag reëel was of geflatteerd, en daarmee of de bookmaker de volgende wedstrijd te hoog of te laag inprijst.
Naast xG zijn er aanvullende metrics als xGA (expected goals against, de defensieve tegenhanger), shot quality, en progressive passes. Elk van deze statistieken voegt een laag toe aan je analyse. Een team met een lage xGA en veel clean sheets is echt goed in verdedigen. Een team met een lage xGA maar weinig clean sheets heeft pech — en pech keert terug naar het gemiddelde. De volledige werking van xG, xGA en shot quality is een onderwerp apart dat meer ruimte verdient dan deze sectie biedt — hier volstaat het om te weten dat deze metrics bestaan, dat ze gratis beschikbaar zijn, en dat ze je analyse naar een hoger niveau tillen zodra je ze integreert in je werkwijze.
Defensieve data: clean sheets, blokken en onderscheppingen
De meeste wedders kijken naar aanvallende statistieken — doelpunten, schoten, xG. Dat is begrijpelijk: doelpunten zijn spectaculair, defensief werk niet. Maar voor wedden is defensieve data minstens zo waardevol, juist omdat het door de markt onderschat wordt.
Clean sheets zijn de meest zichtbare defensieve statistiek, maar ook de meest misleidende — zoals mijn Nantes-voorbeeld aan het begin illustreerde. Een clean sheet vertelt je dat een team geen doelpunt incasseerde, maar niet of dat kwam door goed verdedigen of door geluk. xGA filtert dat verschil eruit. Een team met veel clean sheets en een lage xGA is echt sterk achterin. Een team met veel clean sheets en een hoge xGA is een tikkende tijdbom.
Blokken en onderscheppingen zijn verfijndere metrics die ik gebruik om de stijl van een verdediging te typeren. Een team dat veel blokken registreert, verdedigt doorgaans reactief — ze staan diep en wachten tot de tegenstander schiet. Een team dat veel onderscheppingen maakt, verdedigt proactief — ze zoeken de bal op voordat het schot komt. Beide stijlen kunnen effectief zijn, maar ze reageren anders op verschillende typen tegenstanders. Een reactieve verdediging werkt goed tegen teams die van afstand schieten, maar worstelt tegen teams die de bal geduldig rondspelen en scherpe kansen creëren in het strafschopgebied.
De combinatie van clean sheets, xGA, blokken en onderscheppingen geeft me een profiel van elke verdediging in de Ligue 1. Dat profiel vergelijk ik met het aanvallende profiel van de tegenstander. Een reactieve verdediging tegen een team dat leeft van afstandsschoten: potentieel een clean sheet. Diezelfde verdediging tegen een team dat via korte combinaties door het centrum speelt: potentieel meerdere doelpunten. Die matchup-analyse is precies wat de meeste bookmakers niet volledig in hun modellen verwerken.
Waar vind je betrouwbare Ligue 1 statistieken?
VNLOK, de brancheorganisatie van Nederlandse online kansspelaanbieders, merkte in 2026 op dat de gepubliceerde kanaliseringscijfers niet weergeven waar het geld daadwerkelijk naartoe gaat. Hetzelfde geldt voor voetbalstatistieken: de bron bepaalt de kwaliteit van je analyse, en niet alle bronnen zijn gelijk.
FBref, aangedreven door StatsBomb-data, is mijn primaire bron voor geavanceerde Ligue 1 statistieken. Het platform biedt gratis toegang tot xG, xGA, progressive passes, shot quality en tientallen andere metrics, uitgesplitst per team en per speler. De data wordt doorgaans binnen 24 uur na de wedstrijd bijgewerkt. Het nadeel is dat de interface niet de meest intuïtieve is — het kost een paar sessies om te leren navigeren.
Sofascore is mijn go-to voor snelle basisstatistieken: doelpunten, schoten, balbezit, corners, kaarten. De app is uitstekend voor mobiel gebruik en biedt real-time updates tijdens wedstrijden. Voor diepere analyse is Sofascore onvoldoende, maar als eerste screening is het perfect.
WhoScored combineert kwantitatieve data met visuele weergaven — heat maps, passing networks, spelerbeoordelingen. Die visuele laag helpt me om patronen te herkennen die in kale cijfers verborgen blijven. Waar schiet een team het vaakst? Vanuit welke zone komen de meeste kansen? Die ruimtelijke informatie is bijzonder relevant bij het beoordelen van matchups.
Understat is gespecialiseerd in xG-data en biedt een van de meest gedetailleerde xG-modellen die publiekelijk beschikbaar zijn. Het platform laat je xG filteren per thuiswedstrijd, uitwedstrijd, per seizoensfase en per tegenstander. Die filtermogelijkheden maken het ideaal voor de diepere analyse die ik in de praktijkvoorbeeld-sectie demonstreer.
Mijn werkwijze is een combinatie van deze vier bronnen, elk voor een ander doel. Sofascore voor de eerste screening, FBref voor de diepere analyse, WhoScored voor de visuele patronen, en Understat voor de xG-verificatie. Het kost me per wedstrijd hooguit vijftien minuten om alle relevante data te verzamelen — een investering die zich consistent terugbetaalt in betere weddenschappen. De verleiding is om alles uit een bron te halen, maar elke bron heeft blinde vlekken. Vier perspectieven geven een completer beeld dan een.
Van data naar weddenschap: een praktijkvoorbeeld
Theorie is mooi, maar het bewijs zit in de toepassing. Ik loop een compleet voorbeeld door, van ruwe data naar een concrete weddenschap, zodat je ziet hoe alle stappen samenkomen in de praktijk.
De wedstrijd: Lens thuis tegen Toulouse, een duel in de middenmoot van de Ligue 1. Geen glamourwedstrijd, geen koploper tegen degradatiekandidaat — precies het type wedstrijd waar de bookmaker het minst scherp is en de meeste waarde voor het oprapen ligt.
Stap een: basisstatistieken. Lens staat tiende met 1.4 punten per wedstrijd gemiddeld, maar thuis 1.9 en uit 0.9. Toulouse staat dertiende met 1.1 punten per wedstrijd, thuis 1.5 en uit 0.7. Lens is thuis aanzienlijk sterker, Toulouse is uit kwetsbaar. De gemiddelde stadionbezetting in de Ligue 1 bedraagt 27.375 toeschouwers — Lens zit daar doorgaans boven, met een compact stadion dat een intense atmosfeer creëert. Eerste indruk: Lens favoriet.
Stap twee: doelpuntenpatroon. Lens thuis: gemiddeld 1.6 doelpunten gescoord, 0.9 geïncasseerd. Totaal 2.5 per thuiswedstrijd. Toulouse uit: gemiddeld 0.8 gescoord, 1.7 geïncasseerd. Totaal 2.5 per uitwedstrijd. Het gemiddelde van beide is 2.5 — precies op de standaard over/under lijn. Dat maakt de over/under markt op het eerste gezicht neutraal. Maar we zijn nog niet bij de geavanceerde data.
Stap drie: xG-analyse. Lens thuis heeft een xG van 1.8 per wedstrijd maar scoort gemiddeld 1.6. Ze onderpresteren hun verwachte doelpunten met 0.2 per wedstrijd. Dat kan toeval zijn, maar het kan ook wijzen op een gebrek aan afwerking. Toulouse uit heeft een xGA van 1.4 maar incasseert 1.7. Ze presteren defensief onder hun verwachting — ze geven betere kansen weg dan de uitslagen suggereren. De xG-data zegt: Lens creëert meer kansen dan de resultaten laten zien, en Toulouse geeft minder weg dan de resultaten suggereren. De werkelijke matchup is strakker dan de ruwe doelpuntcijfers doen vermoeden.
Stap vier: defensief profiel. Lens verdedigt reactief — veel blokken, weinig onderscheppingen. Ze staan compact en wachten de tegenstander op. Toulouse speelt uit doorgaans met twee snelle vleugelspelers die op de counter aanvallen. Een reactieve verdediging is kwetsbaar voor de counter, omdat de ruimte achter de linie ontstaat wanneer het blok opschuift na een aanval. Hier zit een mismatch die de basisstatistieken niet laten zien: Lens’ verdedigingsstijl is specifiek kwetsbaar voor Toulouse’ aanvalswapen.
Stap vijf: de markt checken. De bookmaker biedt Lens op 1.75 (implied probability 57,1%), gelijkspel op 3.60 (27,8%), Toulouse op 4.80 (20,8%). Op basis van mijn analyse schat ik Lens op 50-55%, gelijkspel op 25-28%, Toulouse op 18-22%. De thuiszege is door de bookmaker iets te hoog ingeschat — er is marginaal waarde aan de andere kant. Maar marginaal is niet genoeg om te wedden.
Ik verschuif mijn aandacht naar de doelpuntenmarkt. De over 2.5 staat op 1.90 (implied probability 52,6%). Mijn inschatting op basis van de gecombineerde xG-data en het matchupprofiel: de kans op meer dan 2.5 doelpunten is rond de 50%. Geen waarde. Maar de BTTS-markt — beide teams scoren — staat op 1.85 (implied probability 54,1%). Op basis van het feit dat Lens thuis consistent scoort (xG 1.8) en Toulouse’ counterstijl specifiek gevaarlijk is tegen Lens’ reactieve verdediging, schat ik de kans dat beide teams scoren op 60-65%. Dat is waarde.
De weddenschap wordt: BTTS ja bij Lens tegen Toulouse, op 1.85. Het verwachte rendement op basis van mijn inschatting: als de werkelijke kans 62% is en de quotering 1.85, dan is de expected value per 10 euro inzet: (0.62 x 8.50) – (0.38 x 10) = 5.27 – 3.80 = 1.47 euro. Dat is een positieve verwachte waarde van 14,7% — ruim boven de drempel van 3% die ik hanteer.
Dit voorbeeld illustreert waarom statistieken in isolatie misleidend zijn. De ruwe doelpuntcijfers wezen op een neutrale over/under markt. De xG-data nuanceerde dat beeld. Het defensieve profiel onthulde een mismatch. En de synthese van alle drie wees naar een specifieke markt — BTTS — waar de bookmaker de kans onderschatte. Dat is de kracht van data-gedreven wedden: niet meer informatie verzamelen, maar betere informatie combineren.
Wat dit voorbeeld ook laat zien, is dat de uitkomst van het analyseproces niet altijd de voor de hand liggende markt is. Ik begon met de 1X2-markt, vond daar geen waarde, verschoof naar over/under, vond daar geen waarde, en landde uiteindelijk bij BTTS. Die flexibiliteit is cruciaal. Te veel wedders beginnen met een markt in hun hoofd — “ik wil op de thuiszege” — en zoeken vervolgens data die dat bevestigt. Dat is confirmation bias, niet analyse. Laat de data je naar de markt leiden, niet andersom.
Het volledige analyseproces voor deze ene weddenschap kostte me twintig minuten. Dat is de realistische tijdsinvestering per wedstrijd als je de bronnen kent en een vaste werkwijze hebt. In het begin duurt het langer, maar na tien wedstrijden heb je een routine. En die routine is het verschil tussen wedden als hobby en wedden als een gedisciplineerde bezigheid die structureel betere resultaten oplevert dan buikgevoel alleen.
Veelgemaakte fouten bij het interpreteren van voetbalstatistieken
Na negen jaar werken met voetbalstatistieken heb ik een lijstje opgebouwd van fouten die ik keer op keer zie — bij mezelf en bij anderen. De meeste zijn vermijdbaar, mits je ze herkent.
De eerste en meest voorkomende fout is de “kleine steekproef” valkuil. Na drie wedstrijden heeft een speler een xG van 0.1 per wedstrijd maar twee doelpunten gemaakt. Dat lijkt op een fenomenale afwerker. In werkelijkheid is drie wedstrijden te weinig om welke conclusie dan ook te trekken. Ik hanteer als vuistregel een minimum van tien wedstrijden voordat ik een statistiek als betrouwbaar beschouw. Bij teamstatistieken geldt hetzelfde: de eerste vijf speelrondes zijn ruis, niet data.
De tweede fout is het verwarren van correlatie met causaliteit. Een team dat veel corners trapt en veel wedstrijden wint, wint niet noodzakelijk omdat het veel corners trapt. Het trapt veel corners omdat het dominant is en de tegenstander vastpint — de dominantie is de oorzaak van beide. Wedden op “meer dan 8 corners” omdat het team goed presteert, is de verkeerde conclusie uit de juiste data.
De derde fout is het negeren van de context. Marseille met een gemiddelde thuisopkomst van 63.274 en Monaco met 8.164 — die twee clubs opereren in compleet verschillende omstandigheden. Het vergelijken van hun thuisstatistieken zonder die context mee te nemen levert conclusies op die nergens op slaan. Elke statistiek heeft een context, en die context maakt het verschil tussen een nuttig inzicht en een misleidende conclusie.
De vierde fout is data-overload. Meer data is niet per definitie beter. Ik heb fases gehad waarin ik twintig verschillende metrics per wedstrijd raadpleegde en uiteindelijk verlamd raakte door tegenstrijdige signalen. Mijn huidige systeem gebruikt vijf kernmetrics — xG, xGA, punten per wedstrijd thuis/uit, clean sheets, en vorm gecorrigeerd voor tegenstander — en voegt alleen aanvullende data toe wanneer die vijf geen eenduidig beeld geven. Eenvoud is een kracht, geen beperking.
De vijfde fout is het vergeten van seizoensverloop. Statistieken worden doorgaans als seizoensgemiddelden gepresenteerd, maar een seizoen is geen homogeen blok. Een team dat in de eerste tien wedstrijden 1.8 doelpunten per wedstrijd scoort en in de laatste tien 0.9, heeft een seizoensgemiddelde van 1.35 — een getal dat noch de sterke fase noch de zwakke fase weerspiegelt. Ik splits mijn data altijd in blokken van tien wedstrijden om te zien of er een trend is. Die trend is vaak relevanter dan het gemiddelde, vooral na de winterstop wanneer selecties veranderen door transfers en blessures.
Al deze fouten hebben een gemeenschappelijke oorzaak: het behandelen van statistieken als feiten in plaats van als aanwijzingen. Een statistiek is een momentopname, geen voorspelling. Het wordt pas een voorspelling wanneer je het combineert met context, matchup-analyse en een gezonde dosis scepsis over je eigen conclusies.
Veelgestelde vragen over Ligue 1 statistieken en wedden
Welke Ligue 1 statistieken zijn het belangrijkst voor wedden?
De vijf kernstatistieken zijn: expected goals (xG) voor aanvallende kwaliteit, expected goals against (xGA) voor defensieve kwaliteit, punten per wedstrijd gesplitst in thuis en uit, clean sheets in combinatie met xGA, en recente vorm gecorrigeerd voor de kwaliteit van de tegenstander. Deze vijf metrics geven samen een completer beeld dan doelpunten of klassement alleen.
Welke geavanceerde statistieken zijn naast xG nuttig voor Ligue 1 wedders?
Naast xG zijn xGA, shot quality, progressive passes, blokken en onderscheppingen waardevol. xGA helpt bij het beoordelen van defensieve kwaliteit, shot quality verfijnt de xG-analyse, en blokken versus onderscheppingen onthullen de verdedigingsstijl van een team. De combinatie van deze metrics stelt je in staat om matchups te analyseren die basisstatistieken niet laten zien.
Waar vind je gratis geavanceerde statistieken voor de Ligue 1?
FBref biedt de meest uitgebreide gratis xG- en geavanceerde data, aangedreven door StatsBomb. Sofascore is ideaal voor snelle basisstatistieken en live updates. WhoScored combineert data met visuele weergaven als heat maps. Understat is gespecialiseerd in xG-analyse met gedetailleerde filtermogelijkheden per situatie. Alle vier zijn gratis toegankelijk en vormen samen een compleet analytisch arsenaal.
Gemaakt door de redactie van 'Wedden Ligue 1'.